

Bilgisayar bilimlerinde veri sıkıştırmak için kullanılan bir kodlama yöntemidir. Kayıpsız (lossless) olarak veriyir sıkıştırıp tekrar açmak için kullanılır. Huffman kodlamasının en büyük avantajlarından birisi kullanılan karakterlerin frekanslarına göre bir kodlama yapması ve bu sayede sık kullanılan karakterlerin daha az, nadir kullanılan karakterlerin ise daha fazla yer kaplamasını sağlamasıdır.
Şayet bütün karakterlerin dağılımı eşitse yani aynı oranda tekrarlanıyorsa, bu durumda Huffman kodlaması aslında blok sıkıştırma algoritması (örneğin ASCII kodlama) ile aynı başarıya sahiptir. Ancak bu teorik durumun gerçekleşmesi imkansız olduğu için her zaman daha başarılı sonuçlar verir.
Örneğin sadece 8 sembolden oluşan bir dilimiz olsun (Örneğin a,b,c,d,ef,g,h harflerinden oluşan bir dil düşünelim) Bu dili kodlamak için 3 bit yeterlidir (23=8 olduğuna göre 8 farklı dili ikilik tabanda kodlayabiliriz)
Bu durumda örneğin harflerin değerlerini aşağıdaki şekilde oluşturabiliriz:
a 000
b 001
c 010
d 011
e 100
f 101
g 110
h 111
Her harf için farklı bir kodlama yapılan dilde örneğin “baba caddede ebe” mesajını kodlayacak olursak:
001000001000 010000011011100011100 100001100
şeklinde bir sonuç elde ederiz. Görüldüğü üzere kodlama sonucunda harf sayısının üç misli kadar bit kullanılmak zorundadır (14 harf için 14×3=52 bit gerekmektedir).
Huffman kodlaması ile bu mesajı sıkıştıracak olsaydık. Öncelikle harflerin mesajdaki sıklıklarını gösteren biraşağıdaki istatistiğin çıkarılması gerekirdi:
a3b3c1d3e4f0g0h0
Yukarıda her harfin kullanılma sıklıkları sıralanmıştır. Bu istatistiksel veriye dayanarak bir ağaç oluşturulması gerekir.
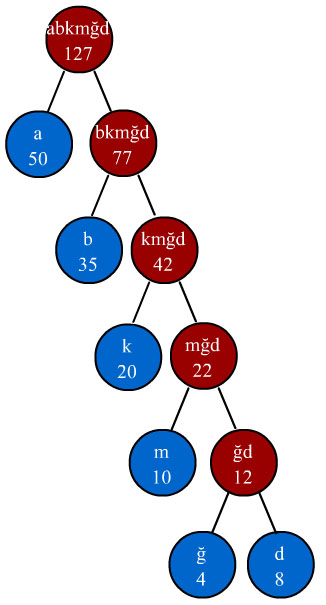
Yukarıdaki ağaçta dikkat edilirse dilimizdeki harfler ve her harf düğümlerinin birleşim noktalarında ise o harflerin mesajdaki tekrar sayıları bulunmaktadır. Ayrıca istatistiksel olarak birbirine denk olan sıklıktaki düğümler aynı seviyede bulunmaktadır. Örneğin g+b = 3 sıklığa sahip ve d’de 3 sıklığa sahiptir. Bu durumda d ile g ve b’nin birleştiği düğüm aynı seviyede olmaktadır.
Yukarıdaki bu ağaca göre her harfi veren kodlama karşılığı çıkarılır. Bu çıkarma işlemi sırasında ağaçtaki her sağ kola hareket 1, her sol kola hareket 0 olarak okunur. Örneğin g harfinin değeri 010’dır çünkü kökteki 14 değerinin solunda (yani 0) 6 değerinin sağında (yani 1) ve 3 değerinin solundadır yani toplamda 010 değerine sahiptir.
Bu şekilde her harfin kodlama değeri aşağıda verilmiştir:
a 111
b 011
c 110
d 00
e 10
g 010
Yukarıdaki bu kodlamaya göre ilk mesajımızın yeni değeri :
011111011111 1101110000100010 1001110
Şeklinde bulunmuş olur. Dikkat edilirse bu mesajın boyutu 36 bittir ve ilk baştaki 52 bit uzunluğundan daha kısadır.
Huffman Ağacının Oluşturulması
Genel bir soru üzerine, ağacın oluşturulma algoritmasını yayınlıyorum. Ağacı oluşturmanın çeşitli algoritmaları olduğu gibi, en basit olanı, bir rüçhan sırası (öncelik sırası, priority queue) kullanmaktır. Bu sırada, en düşük olasılığa sahip olan düğüm (node), en yüksek rüçhana sahip olacaktır. Algoritmanın adımları aşağıdaki şekildedir:
1. Algoritma tarafından kodlanacak olan her sembol için birer yaprak düğüm, rüçhan sırasına eklenir.
2. Sırada, birden fazla düğüm kaldığı sürece aşağıdaki adımlar döngü halinde yapılır.
a. Sıradan, en yüksek rüçhana sahip iki düğüm alınır. (bu düğümlerin en az kullanım sıklığına sahip olduğunu hatırlayınız)
b. Yeni bir iç düğüm (internal node) oluşturulup, değer olarak bu alınan iki düğümün toplamı atanır.
c. Yeni düğüm ağaca ve sıraya eklenir.
3. Döngü bitip tek düğüm kaldıysa, bu düğüm, kök düğüm yapılır ve algoritma sona erer.
2. Sırada, birden fazla düğüm kaldığı sürece aşağıdaki adımlar döngü halinde yapılır.
a. Sıradan, en yüksek rüçhana sahip iki düğüm alınır. (bu düğümlerin en az kullanım sıklığına sahip olduğunu hatırlayınız)
b. Yeni bir iç düğüm (internal node) oluşturulup, değer olarak bu alınan iki düğümün toplamı atanır.
c. Yeni düğüm ağaca ve sıraya eklenir.
3. Döngü bitip tek düğüm kaldıysa, bu düğüm, kök düğüm yapılır ve algoritma sona erer.
Şimdi, yukarıdaki bu algoritmaya göre ağacımızı oluşturalım. Harfler ve kullanım sıklıkları aşağıdaki şekildedir:
e4,d3,a3,b3,c1
Buna göre bir rüçhan sırası yaparsak:
c1,b3, a3, d3, e4 şeklinde en düşük sıklığa sahip olan en önde olacaktır.(ayrıca eşit öncelikli olanlar, kendi aralarında istenildiği gibi sıralanabilir.)
Algoritmanın 2. adımına geçiyor ve döngümüzü çalıştırmaya başlıyoruz.
Sıradaki en yüksek rüçhana sahip iki düğümü alalım: c1, b3
Toplamlarını hesaplayalım: 1+3 = 4
Yeni çıkan bu düğümü ağaca ve sıraya ekleyelim.
#include <stdio.h>
#include <stdlib.h>
#include <windows.h>
typedef struct huffman{
int frekans;
char data;
struct huffman *sol,*sag;
}LST;
int main(){
LST *kok,*gez,*ekle,*ekle1;
kok=gez=new LST;
char dizi[]={'a','p','t','y','\0'};
int dizif[]={3,2,1,1,'\0'};
kok->sag=NULL; kok->sol=NULL;
int toplam=0;
for(int i=0;dizi[i]!='\0';i++){
toplam+=dizif[i];
}
kok->frekans=toplam;
for(int i=0;dizi[i]!='\0';i++){
ekle=new LST;
ekle->sag=NULL; ekle->sol=NULL;
ekle->data=dizi[i];
toplam-=dizif[i];
if(dizi[i+2]!='\0'){
ekle1=new LST;
ekle1->sag=NULL; gez->sol=NULL;
ekle1->frekans=toplam;
}
else{
ekle1=new LST;
ekle1->sag=NULL; gez->sol=NULL;
ekle1->data=dizi[i+1];
}
gez->sol=ekle;
gez->sag=ekle1;
gez=gez->sag;
}
bool sakla[]={1,0,0,1,1,0};
gez=kok;
for(int i=0;i<7;i++){
if(sakla[i]==0){
gez=gez->sol;
printf("%c",gez->data);
gez=kok;
}
else{
gez=gez->sag;
if(gez->sag==NULL){
printf("%c",gez->data);
gez=kok;
}
}
}
system("pause");
return 0;
}




{kind=link}
0 Yorumlar
Bizimle fikirlerinizi paylaşabilirsiniz.